让我们用Python去做一个Jarvis吧!
这一部分主要是语音识别部分的Python实现,而且由于这是我利用课余时间而作,所以相对于其他的项目而言进度可能并不会特别迅速,更新缓慢且随缘。
序
那我们就从前面的框架开始动手实现我们的 Jarvis,首先给大家看一下我的文件目录框架:
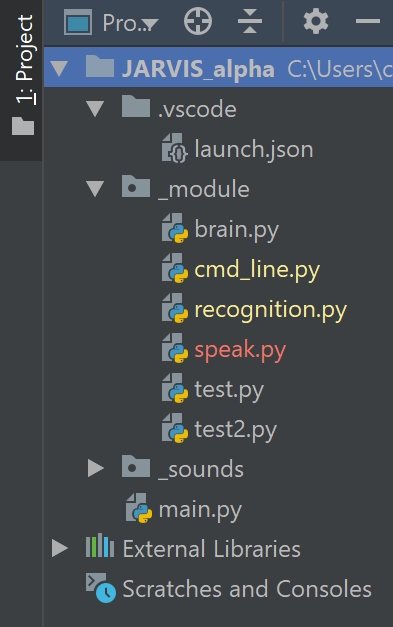
其中我把所有自己写的py模块统一归入_module文件夹,供main.py调取,_sounds文件夹存着因为语音识别以及TTS产生的音频文件。
因为目前的结构还不是特别庞大,可能后面会因为管理或者功能增加等等的原因进行修正。如果有改动我会在后面进行补充。
作为一个懒人程序员,并且本着不重复造轮子的原则,我决定先到网上搜一搜有没有现成的解决方案能够直接使用的。
Emmm… 貌似没有,但这并不影响我们的功能实现。
我们把语音识别的问题拆分开来,便是:
- 麦克风录音
- 语音识别成文本
- 返回文本
然而幸运的是,百度在语音识别方面有着成熟的API以及SDK提供使用,所以在这个方面我们真正需要自己实现的部分只有录音方面了。
后期补充:目前我将这一方面的算法转用腾讯 AI 平台实现,并为此写了一套 SDK,如有需要的话可以参考我的项目。 这并不影响下面百度平台的实现。
语音录入生成.wav文件
我将语音录入的方法写在了recognition.py中,与语音识别等功能放在一起便于调用和管理,后续编辑也会方便一些。
在语音录入方面我们需要调用Pyaudio和wave模块,如果没有安装的话可以通过pip、conda或者Pycharm安装,方法这里就不赘述了。
然后首先我们需要导入这两个模块:
import pyaudio
import wave
然后便是具体的方法实现,我写了一个def audio_record,这个部分的功能便完成了录音,并且会将录音保存为.wav格式。
def audio_record(out_file, rec_time): # out_file:输出音频文件名, rec_time:音频录制时间(秒)
CHUNK = 1024
FORMAT = pyaudio.paInt16 # 16bit编码格式
CHANNELS = 1 # 单声道
RATE = 16000 # 16000采样频率
p = pyaudio.PyAudio()
# 创建音频流
stream = p.open(format=FORMAT, # 音频流wav格式
channels=CHANNELS, # 单声道
rate=RATE, # 采样率16000
input=True,
frames_per_buffer=CHUNK)
print("I'm listening...")
frames = [] # 录制的音频流
# 录制音频数据
for i in range(0, int(RATE / CHUNK * rec_time)):
data = stream.read(CHUNK)
frames.append(data)
# 录制完成
stream.stop_stream()
stream.close()
p.terminate()
print("Emmm...")
# 保存音频文件
wf = wave.open(out_file, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
这样就实现了程序自动录音然后自动保存为.wav文件的过程,其中的rec_time是录音的固定时长,经过我的多次测试最终设置为了一个较合理的5秒时长,这个见仁见智,可以根据自己的使用情况做改动。
STT——语音转文字
接下来就是要让“Jarvis”听到我们说的话,也就是STT——声音转文字的功能实现。
我们需要用到百度的开放平台,所以首先需要有一个百度的AI开放平台的账号,这个可以直接前往百度AI开放平台注册。
这里为什么我会选择使用百度而非高德的语音识别平台呢?
识别体验大同小异,高德标点符号更完善些。高德对于开发者有着500次每日的额度限制,而百度是无限次数的。不用考虑了,选腾讯老大哥吧。腾讯 AI 平台现在也开始商用了,限制了开发者的 API 调用次数,如果对次数有要求的话还是百度吧
注册完后需要在百度AI平台的语音技术一栏新建一个应用,并且将语音识别加入到应用的功能中,其它的功能有按需加入。
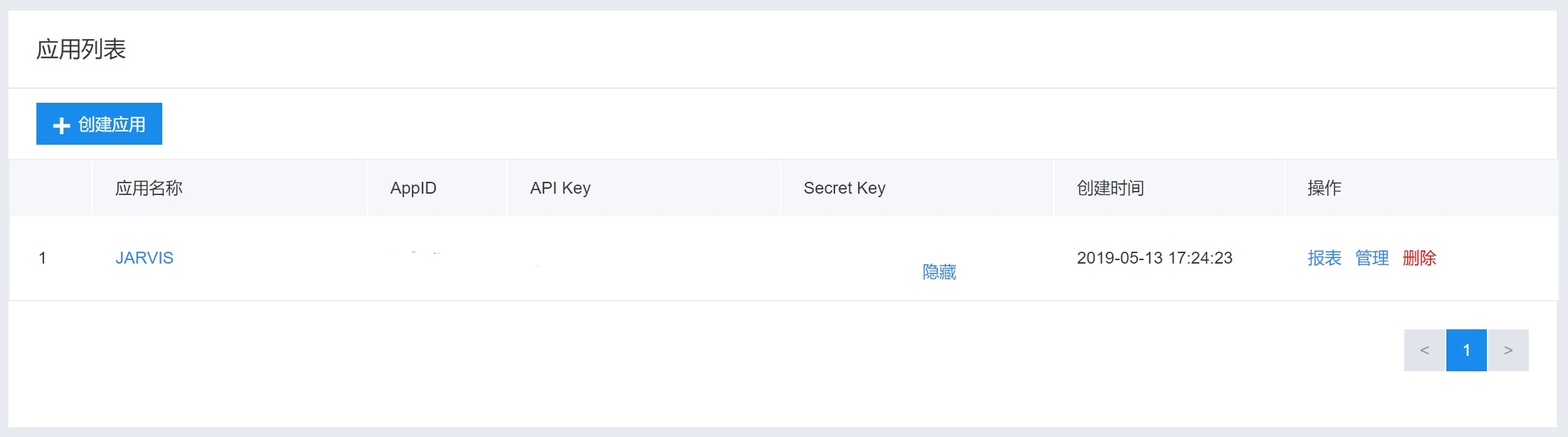
这个时候进入管理应用页面,就可以看到我们所创建的应用以及对应的APPID、API Key、Secret Key。这三个参数是我们后续接入百度平台的必备条件。
然后我们开始完成语音转文字的代码部分。
首先导入aip模块,这个模块只能通过pip install aip进行安装,或者自己从百度的SDK页面下载导入。
from aip import AipSpeech
然后将其实例化并建立一个基于我们应用的对象,方便后续调用。
APP_ID = '' # App ID
API_KEY = '' # API Key
SECRET_KEY = '' # Secret Key
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
然后查了一下aip的方法中,asr对应的是语音识别的方法,所以我们直接调用asr方法就行,然后在设置一个识别失败的默认恢复。
代码如下:
def BaiduRecog(fileurl):
try:
res = client.asr(Recognition.get_file_content(fileurl), 'pcm', 16000, {
'dev_pid': 1537,
})
return res['result'][0]
except:
return 'Pardon?'
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
上面代码中的dev_pid是一串设置的代码,每一个数字对应一个参数,在百度AI平台的SDK文档中有说明。
在我先前百度过的语音识别方法中,绝大多数都是先录下来
wav文件,然后转换为mp3文件再上传至百度平台进行识别,并没有其他他别好的方案。 考虑到算法的时效性,wav转换为mp3这一个环节的存在完全没有必要,可以去掉,所以我把算法改成了直接将录下来的wav传到百度平台进行分析,相较他人减少了一个步骤。
我们还差最后一步,把识别到的文字显示到控制台上。若果需要一直进行语音识别可以直接套上While True循环。
audio_record('temp.wav', 5)
voice = Recognition.BaiduRecog('temp.wav')
print(voice)
输出结果如下:
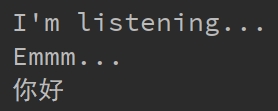
至此,语音识别就已经完成了。
下一次我会介绍一下我实现对文字的自动回复以及让“Jarvis”说话的TTS部分。
Peace.
